1. 스프링 부트 3 구조 살펴보기
- 계층
: 각자의 역할과 책임이 있는 어떤 소프트웨어의 구성 요소를 의미
→ 각 계층은 소통 가능하지만, 직접 간섭하거나 영향을 미치지 않음
1) 스프링 부트의 계층 알아보기
프레젠테이션 계층 <---> 비즈니스 계층 <---> 퍼시스턴스 계층 <---> 데이터베이스
컨트롤러 서비스 레포지토리
◉ 프레젠테이션 계층
• HTTP 요청을 받고 이 요청을 비즈니스 계층으로 전송하는 역할 → 컨트롤러
• 컨트롤러는 스프링 부트 내에 여러 개가 있을 수 있음
◉ 비즈니스 계층
• 모든 비즈니스 로직을 처리 → 서비스
◉ 퍼시스턴스 계층
• 모든 데이터베이스 관련 로직을 처리 → 레포지토리
• 이 과정에서 데이터베이스에 접근하는 DAO 객체 사용 가능
→ DAO : 데이터베이스 계층과 상호작용하기 위한 객체
⇒ 계층 : 개념의 영역
컨트롤러, 서비스, 리포지토리 : 실제 구현을 하는 영역
2) 스프링 부트 프로젝트 디렉터리 구성하며 살펴보기
◉ main
- 실제 코드를 작성하는 공간
→ 프로젝트 실행에 필요한 소스 코드나 리소스 파일은 모두 이 폴더 안에 존재
◉ test
: 프로젝트의 소스 코드를 테스트할 목적의 코드나 리소스 파일이 들어있음
◉ build.gradle
: 빌드를 설정하는 파일 → 의존성이나 플러그인 설정 등과 같이 빌드에 필요한 설정을 할 때 사용
◉ setting.gradle
: 빌드할 프로젝트의 정보를 설정하는 파일
3) main 디렉터리 구성하기
① /resource/templates : HTML과 같은 뷰 관련 파일
② /resource/static : JS, CSS, 이미지와 같은 정적 파일
③ /webapp/WEB-INF/view : JSP 파일
④ /resource에 application.properties 파일 대신 application.yml 파일 생성 ( 확장자 변경하면 됨 )
→ 스프링 부트 서버가 실행되면 자동으로 로딩되는 파일 ( 데이터베이스의 설정 정보, 로깅 설정 정보 등 )
: application.yml의 경우, application.properties에 비해 중복되는 코드는 제거하므로 가독성 높으며 설정파일의 오류 찾기 쉬움
• 중복되는 코드 삭제 / 들여쓰기
• '=' 대신 ':'(콜론)
• 주석 : '#'

2. 스프링 부트 3 프로젝트 발전시키기
◉ 의존성 추가 → 프레젠테이션 계층 → 비즈니스 계층 → 퍼시스턴스 계층 순으로 코드 작성
1) build.gradle에 의존성 추가하기
① build.gradle에 필요한 의존성 추가
▪︎ 스프링 부트용 JPA인 스프링 데이터 JPA(Java Persistence API)
: 자바 객체와 데이터베이스를 연결해 데이터를 관리 / 객체 지향 도메인 모델과 데이터베이스의 다리 역할
▪︎ 로컬 환경과 테스트 환경에서 사용할 인메모리 데이터베이스인 H2
▪︎ 반복 메서드 작성 작업을 줄여주는 라이브러리인 롬복

② 의존성 추가 후, 반드시 Refresh Gradle Project 해주기
▪︎ 내장형 DB(In-memory DB)란?
- 디스크 베이스 DB와 반대로 메모리에 데이터를 저장하는 것을 인메모리 DB라고 함
- 외부 저장 장치에 데이터를 저장하지 않고 메모리에서 데이터를 읽고 쓰기 때문에 디스크 베이스 DB에 비해 데이터 이용 속도가 빠른 편
- H2
• 자바 기반의 오픈소스 RDBMS
• 브라우저 기반의 콘솔 모드를 이용할 수 있으며 설치과정이 불필요
• 인메모리 DB를 지원하며 디스크 테이블도 생성 가능
• 내장모드 & 서버모드 모두 지원
• 가성비가 좋으나, 안정성 문제로 소규모 프로젝트의 테스트용으로 사용
[ 참고자료 ]
https://cyberx.tistory.com/308
2) 프레젠테이션, 서비스, 퍼시스턴스 계층 만들기
◉ 프레젠테이션 계층 - LayerController 생성
package org.choongang.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.ResponseBody;
@Controller
@ResponseBody
// 위의 두 가지 애너테이션이 합쳐진 것이 '@RestController'
public class LayerController {
@Autowired // → 멤버 변수에 의존성 주입을 통해 초기화시킴
// 스프링 부트 컨테이너가 LayerService 객체(빈)를 만들어 제공함
LayerService layerService;
@GetMapping("/hello") // 웹 브라우저가 '/hello'로 요청을 하면,
// getAllMembers() 메서드가 처리함
public List<Member> getAllMembers() {
List<Member> members = layerService.getAllMembers();
// 서비스로부터 데이터를 리스트형태로 받아옴
return members;
}
}❶ @RestController
▪︎ 라우터 역할로, @Controller 애너테이션에 @ResponseBody 애너테이션이 합쳐진 결과물
- @ResponseBody : HTTP 요청 Body를 자바 객체로 전달 받을 수 있음
▪︎ @RestController
: @Controller와 다르게 리턴값에 자동으로 @ResponseBody가 붙게 되어 별도 어노테이션을 명시해주지 않아도 HTTP 응답데이터(Body)에 자바 객체가 매핑되어 전달됨
▪︎ @Controller의 경우, Body를 자바 객체로 받기 위해서는 @ResponseBody 어노테이션을 반드시 명시해주어야 함
❷ @Autowired
- 필요한 의존 객체의 타입에 해당하는 빈을 찾아 주입함
- 다음 3가지 경우에 @Autowired 어노테이션 사용 가능
• 생성자 ( 생성자를 통해 의존성 주입하는 것을 권장 )
• setter
• 필드
▪︎ @RequestBody /@ResponseBody 정리
- 클라이언트에서 서버로 필요한 데이터를 요청하기 위해 JSON 데이터를 요청 본문에 담아서 서버로 보내면,
서버에서는 @RequestBody 어노테이션을 사용하여 HTTP 요청 본문에 담긴 값들을 자바 객체로 변환시켜, 객체에 저장함
- 서버에서 클라이언트로 응답 데이터를 전송하기 위해 @ResponseBody 어노테이션을 사용하여 자바 객체를 HTTP 응답 본문의 객체로 변환하여 클라이언트로 전송함
[ 참고 자료 ]
https://cheershennah.tistory.com/179
◉ 비즈니스 계층 - LayerService 생성
- MemberRepository라는 빈을 주입받은 후에, findAll( ) 메서드를 호출해 멤버 테이블에 저장된 멤버 목록을 모두 가져옴
package org.choongang.service;
import java.util.List;
import org.choongang.domain.Member;
import org.choongang.domain.MemberRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class LayerService {
@Autowired
MemberRepository memberRepository; // ❶ 빈 주입
// * 비즈니스 로직 처리 메서드로, 모든 회원 명단을 가져오게 됨
public List<Member> getAllMembers() {
return memberRepository.findAll(); // ❷ 멤버 목록 얻기
}
}▪︎ @Service
- 비즈니스 로직 처리
- @Service 애너테이션 : @Component 포함 → 해당 클래스를 스프링 컨테이너에 빈 객체로 생성하는 역할
- 서비스의 역할
• 유동적으로 변하는 데이터를 정제하는 작업 수행
▪︎ 데이터베이스와의 작업은 모델에서 수행 → Repository 객체가 필요함
▪︎ @Autowired 애너테이션을 사용해 스프링 컨테이너가 MemberRepository 객체(빈) 생성 및 관리
→ 스프링 컨테이너가 생성된 MemberRepository 객체를 서비스에게 전달해줌
▪︎ Repository 객체의 findAll() 메서드를 이용해 모든 데이터를 가져옴
→ 이 메서드는 JpaRepository 인터페이스에 구현되어 있음 ( 상속받고 사용하면 됨 )
- 실제 구현은 Hibernate 객체가 구현함
- 스프링 부트에서 데이터베이스 처리
: JPA → MyBatis → JDBC 순대로 진행
• 기본 JPA : SQL 필요없이 JPA가 자동으로 자동으로 생성하고 사용함
• 기본 MyBatis : SQL만 별도 설정파일에 기술해주면 MyBatis 라이브러리가 메서드를 자동 생성함
• 기본 JDBC : 모든 데이터 베이스 코드르 직접 다루어야 함 (제일 코딩이 어려운 편 )
◉ 퍼시스턴스 계층 - Member 생성
- DB에 접근할 때 사용할 객체인 Member DAO를 생성하고, 실제 DB에 접근하는 코드 작성
package org.choongang.domain;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import lombok.AccessLevel;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
@NoArgsConstructor(access=AccessLevel.PROTECTED)
@AllArgsConstructor
@Getter // 데이터가 한번 만들어지면 고칠 수 없도록 설정 (VO 형식)
@Entity // 모델 클래스와 데이터 클래스를 1:1로 동기화함
// 데이터베이스 테이블의 구조와 동등 -> JPA가 만듦
public class Member {
@Id
// 일련번호로 Primary Key를 사용함
@GeneratedValue(strategy=GenerationType.IDENTITY)
// GeneratedValue : 자동생성된다는 의미
// strategy : 만드는 방식, 전략 -> 자동으로 일련번호를 만들어서 사용하라
@Column(name="id", updatable=false)
private Long id;
// 테이블의 'id' 컬럼과 매핑
@Column(name="name", nullable=false)
private String name;
}▪︎ @Id
- Long 타입의 id 필드를 테이블의 기본키로 지정
▪︎ @GeneratedValue
- 기본키의 생성 방식 결정
- strategy : 만드는 방식 지정
• IDENTITY : 기본 키 생성을 데이터베이스에 위임 ( = AUTO_INCREMENT )
▪︎ @Column
- 보통 해당 테이블의 컬럼명과 다른 멤버변수 이름으로 사용하고 싶은 경우에 사용
- 주로 테이블의 컬럼명의 경우, 스네이크 표기법 선호 ( 밑줄 _ 사용 )
자바의 경우, 대소문자의 카멜표기법 선호
⇒ 두 명칭이 표기법으로 인해 불일치할 경우, JPA가 해당 컬럼을 연결하지 못하는 상황 발생
- 따라서, 명시적으로 @Column 애너테이션을 사용하여 매핑해줌
동시에 중요 속성이 있는 경우에도 사용함 ( 추후 배울 예정, 우선 위의 코드에 나온 것만 정리해보자 )
❶ name : 필드와 매핑할 컬럼 이름. 설정하지 않으면 필드 이름으로 지정해줌.
❷ nullable : 컬럼의 null 허용 여부. 설정하지 않으면 true(nullable)
❸ updatable : 컬럼의 update 허용 여부.
⇒ member 테이블에 접근하는 데 사용하는 객체 정도로 일단 이해하고 넘어가자
◉ 매핑 작업 - MemberRepository 인터페이스 필요
- 실제로 member 테이블과 Member 클래스를 매핑하기 위해서는 인터페이스 파일이 필요함
→ MemberRepository.java 인터페이스 파일을 생성해보자
- DB에서 데이터를 가져오는 퍼시스턴트 계층 역할
즉, member 테이블에 접근해서 Member 클래스에 매핑하는 구현체
package org.choongang.domain;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface MemberRepository extends JpaRepository<Member, Long>{
}
3. 임포트 오류 처리하기
◉ 임포트 순서 : 내가 만든 클래스 → java → javax → jakarta 순
4. 작동 확인하기
◉ 각 계층의 코드 완성했으니, 스프링 부트 애플리케이션을 실행해보자
- 현재는 결과물을 볼 수 있는 데이터가 데이터베이스에 하나도 입력되지 않은 상태
- 보통 이런 실행 테스트를 위해 애플리케이션을 실행할 때마다 SQL문을 실행해 데이터베이스에 직접 데이터를 넣음
- 지금은 인메모리 데이터베이스인 H2를 사용 → 애플리케이션을 새로 실행할 때마다 데이터가 사라져 매우 불편함
→ 이를 해결하기 위해 애플리케이션을 실행할 때 원하는 데이터를 자동으로 넣는 작업을 해보자.
① 애플리케이션이 실행될 때 저장할 더미 데이터를 넣을 SQL 파일을 생성해보자
: jsp 파일로 생성한 후, INSERT문 추가 → webapp에 있는 jsp파일을 resources 폴더로 옮긴 후, 확장자를 .sql로 변경

INSERT INTO member (id, name) VALUES (1, '구름');
INSERT INTO member (id, name) VALUES (2, '하늘');
INSERT INTO member (id, name) VALUES (3, '산');
INSERT INTO member (id, name) VALUES (4, '바다');
INSERT INTO member (id, name) VALUES (5, '비');
▪︎ 더미 데이터(Dummy Data)란?
- 유용한 데이터가 포함되지는 않지만, 공간을 예비해두어 실제 데이터가 명목상 존재하는 것처럼 다루는 정보
- 언제 사용할까?
여러 건의 물리적 데이터를 이용하여 테스트할 때 사용
② application.yml 파일의 코드 변경
server :
port: 80
spring :
mvc: # spring.mvc
view: # spring.mvc.view
prefix: /WEB-INF/view/ # spring.mvc.view.prefix=/WEB-INF/view/
suffix: .jsp # spring.mvc.view.suffix=.jsp
# datasource:
# driver-class-name: oracle.jdbc.OracleDriver
# url: jdbc:oracle:thin:@localhost:1521/xe
# username: webuser
# password: webuser
jpa:
# 실제 데이터베이스로 전송되어 처리되는 쿼리 내용을 보여라
show-sql: true
properties:
hibernate:
# jpa 구현 hibernate에서 sql를 형식 정렬하여 사용하라
format_sql: true
# 테이블 생성 후에 data.sql 실행
# 메모리 데이터베이스를 사용하면 스프링 부트 앱을 실행할 때마다
# 모든 데이터를 지워버리고 다시 만든다. 그 때 기초 데이터로 사용하기 위해
# 지정한 sql 파일을 사용하라는 뜻
# schema.sql : 테이블 구조 만들기 - DDL
# data.sql : 테이블에 데이터 추가 등 - DML
defer-datasource-initialization: true❶ show-sql, format_sql 옵션 : 애플리케이션 실행 과정에서 데이터베이스에 쿼리를 할 일이 있으면 실행 구문을 모두 보여주는 옵션
❷ defer-datasource-initialization 옵션 : 애플리케이션을 실행할 때 테이블을 생성하고 data.sql 파일에 있는 쿼리를 실행하도록 하는 옵션
③ 실행해보자
: Console창에서 오른쪽 클릭 - Find/Replace 클릭 : ‘CREATE TABLE’ 검색


④ 포스트맨에서 HTTP 요청 시도
- HTTP 메서드 : GET / URL : http://localhost:80/hello → [ Send ] 클릭해 스프링 부트 서버에 HTTP 요청 전송
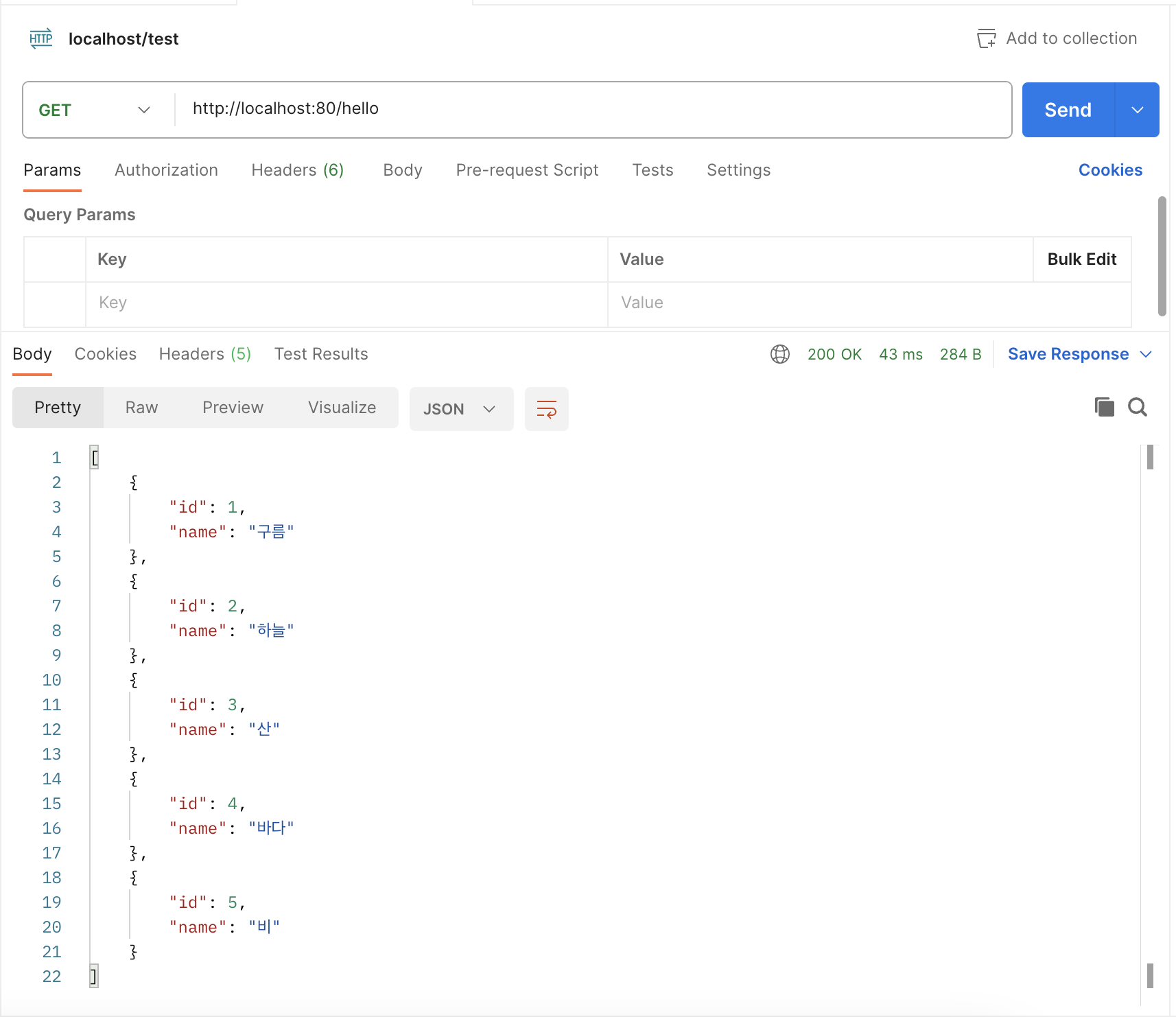
3. 스프링 부트 요청 - 응답 과정 한 방에 이해하기 ★★★
◉ 스프링 부트의 전체적인 실행과정
HTTP 요청
--------------> LayerController.java <---> LayerService.java <---> MemberRepository.java <---> DB
url:/hello 프레젠테이션 계층 비즈니스 계층 퍼시스턴스 계층
① 포스트맨에서 톰캣에 '/hello'로 GET 요청 → 스프링 부트 내로 요청 이동
② 스프링 부트의 Dispatcher Servlet이 URL 분석 후, 이 요청을 처리할 수 있는 컨트롤러 찾음
→ LayerController가 '/hello'라는 경로에 대한 GET 요청을 처리할 수 있는 getAllMembers( ) 메서드를 가지고 있으므로, Dispatcher Servlet가 해당 컨트롤러에게 요청을 전달함
③ getAllMembers( ) 메서드에서는 비즈니스 계층과 퍼시스턴스 계층을 통하면서 필요한 데이터를 가져옴
④ View Resolver는 템플릿 엔진을 사용해 HTML 문서를 만들거나 JSON, XML 등의 데이터를 생성함
⑤ 그 결과, members를 return하고 그 데이터를 포스트맨에서 볼 수 있음
▪︎ Dispatcher Servlet란?
• HTTP 프로토콜로 들어오는 모든 요청을 가장 먼저 받아 적합한 컨트롤러에 위임해주는 프론트 컨트롤러(Front Controller)
• 해당 어플리케이션으로 들어오는 모든 요청을 핸들링해주고 공통 작업을 처리면서 상당히 편리하게 이용
• Dispatcher Servlet의 처리 과정
❶ 클라이언트로부터 어떠한 요청이 오면 Tomcat(톰캣)과 같은 서블릿 컨테이너가 요청을 받음
( 모든 요청은 프론트 컨트롤러인 Dispatcher Servlet이 가장 먼저 받게 됨 )
❷ 디스패처 서블릿은 공통적인 작업을 먼저 처리한 후에 해당 요청을 처리해야 하는 컨트롤러를 찾아서 작업을 위임
• Dispatcher Servlet의 장점
: 해당 어플리케이션으로 들어오는 모든 요청을 핸들링해주며, 공통 작업을 처리
→ 컨트롤러를 구현해두기만 하면, Dispatcher Servlet가 알아서 적합한 컨트롤러로 위임해주는 구조
- Front Controller(프론트 컨트롤러)란?
• 주로 서블릿 컨테이너의 제일 앞에서 서버로 들어오는 클라이언트의 모든 요청을 받아서 처리해주는 컨트롤러
• MVC 구조에서 함께 사용되는 디자인 패턴
[ 참고 자료 ]
https://mangkyu.tistory.com/18
▪︎ 템플릿 엔진(Template Engine)이란?
- 지정된 템플릿 양식과 데이터가 합쳐져 HTML 문서를 출력하는 소프트웨어
→ 웹 사이트 화면을 어떤 형태로 만들지 도와주는 양식
- view code(HTML)와 data logic code(DB Connection)를 분리해주는 기능을 함
- 템플릿 엔진은 서버 사이드 템플릿 엔진과 클라이언트 사이드 템플릿 엔진으로 분류됨
① 서버 사이드 템플릿 엔진 (Server Side Template Engine)
• 서버에서 DB 혹은 API에서 가져온 데이터를 미리 정의된 Template에 넣어 HTML를 그려서 클라이언트에 전달해주는 역할
• 대표적인 서버 사이드 템플릿 엔진 : Thymeleaf, JSP, Freemarker
② 클라이언트 사이드 템플릿 엔진 (Client Side Template)
• HTML 형태로 코드를 작성할 수 있으며, 동적으로 DOM를 그리게 해주는 역할
• 데이터를 받아서 DOM 객체에 동적으로 그려주는 프로세스를 담당
• 대표적인 클라이언트 사이드 템플릿 엔진 : Mustache, Squirrelly, Handlebars
'백엔드 > Spring Boot' 카테고리의 다른 글
| 5. 데이터베이스 조작이 편해지는 ORM (1) - 데이터베이스, ORM (0) | 2023.07.17 |
|---|---|
| 4. 스프링 부트 3와 테스트 (0) | 2023.07.14 |
| 2. 스프링 부트 시작하기 (2) - 스프링 부트 둘러보고 코드 이해하기 (0) | 2023.07.11 |
| 2. 스프링 부트 시작하기 (1) - 스프링 콘셉트 공부 (0) | 2023.07.10 |
| 48, 49 - Spring Boot : 회원가입 게시판 생성 (1) (0) | 2023.07.07 |