GROUP BY에서 조건절 HAVING 추가
• 그룹 질의 결과물 내에서 특정 내용만들 다시 가져오려면 HAVING 조건절 사용
• WHERE : 그룹화하기 전의 조건 설정
HAVING : 그룹화한 후의 조건 설정
※ GROUP BY절이 그룹 지정!
그룹에 대한 조건 지정 시, WHERE절이 아닌 HAVING절 사용
※ WHERE 절에는 MAX, SUM, AVG 등과 같은 집계함수 사용 불가
• 구문
SELECT 컬럼명
FROM 테이블명
WHERE 그룹화하기 전 조건 (전체 테이블에 적용)
GROUP BY 그룹화할 컬럼명
HAVING 그룹화한 후의 조건 (그룹화한 컬럼에 적용)
ORDER BY 컬럼명 ;
SELECT
STATION_NAME,
BOARD_TIME,
GUBUN,
MIN(PASSENGER_NUMBER) AS MIN_VALUE,
MAX(PASSENGER_NUMBER) AS MAX_VALUE,
SUM(PASSENGER_NUMBER) AS SUM_VALUE
FROM SUBWAY_STATISTICS ss
WHERE STATION_NAME IN('구로디지털단지(232)')
GROUP BY STATION_NAME, BOARD_TIME, GUBUN
ORDER BY STATION_NAME, BOARD_TIME, GUBUN
-- 하차 시, 지하철 역별 최대 및 최소 승객수 조회 (WHERE절 대신 HAVING 이용)
SELECT
STATION_NAME,
BOARD_TIME,
GUBUN,
MIN(PASSENGER_NUMBER) AS MIN_VALUE,
MAX(PASSENGER_NUMBER) AS MAX_VALUE,
SUM(PASSENGER_NUMBER) AS SUM_VALUE
FROM SUBWAY_STATISTICS
GROUP BY STATION_NAME, BOARD_TIME, GUBUN
HAVING GUBUN = '하차'
ORDER BY 6 DESC;
-- 추가 ) 최대 승객수가 10000명 이상, 15000명 이하인 데이터 조회
-- WHERE절 : 집계함수 사용 불가
SELECT
STATION_NAME,
BOARD_TIME,
GUBUN,
MIN(PASSENGER_NUMBER) AS MIN_VALUE,
MAX(PASSENGER_NUMBER) AS MAX_VALUE,
SUM(PASSENGER_NUMBER) AS SUM_VALUE
FROM SUBWAY_STATISTICS
WHERE GUBUN = '하차'
GROUP BY STATION_NAME, BOARD_TIME, GUBUN
HAVING MAX(PASSENGER_NUMBER) BETWEEN 10000 AND 15000
ORDER BY 6 DESC;
-- ORDER BY SUM_VALUE DESC와 동일
-- : 컬럼 인데스명 또는 별칭 가능
집합 연산자를 이용한 통합 질의
• 형식
SELECT 속성명1, 속성명2, ...
FROM 테이블명
WHERE 조건
UNION | UNION ALL | INTERSECT | EXCEPT
SELECT 속성명1, 속성명2, ...
FROM 테이블명
WHERE 조건
ORDER BY 속성명 [ ASC | DESC ] ;
// 정렬 시, 첫 번째 테이블의 컬럼명 이용
( 주의 ) 첫 번째 테이블에서 테이블 별명 사용하기 때문에, 정렬시 컬럼명에 별칭을 사용한다면 오류 발생함
※ 두 개의 SELECT문에 기술한 속성들은 개수와 데이터 유형이 서로 동일해야 함
( 컬럼명은 같을 필요 없음 )
→ 조회 결과는 첫 번째 테이블의 컬럼명을 기준으로 함
※ 집합연산자 결과 생성된 테이블을 SELECT 질의 결과 View라고 함
• 집합 연산자의 종류
① UNION : 합집합
- 두 SELECT문의 조회 결과를 통합하여 모두 출력함
- 중복된 행은 한 번만 출력
② UNOIN ALL : 합집합
- 두 SELECT문의 조회 결과를 통합하여 모두 출력함
- 중복된 행도 그대로 출력
③ INTERSECT : 교집합
- 두 SELECT문의 조회 결과 중 공통된 행만 출력함
④ MINUS : 차집합
- 첫번째 SELECT문의 조회 결과에서 두 번째 SELECT문의 조회 결과를 제외한 행을 출력함
※ Oracle에서는 MINUS 연산자 이용 ( 다른 데이터베이스의 EXCEPT 연산자와 비슷한 기능 )
연습
- 집합 연산자 예시를 위한 테이블 생성 및 데이터 추가
-- 집합 쿼리 실습을 위한 첫번째 테이블 생성 : MEMBER 테이블
CREATE TABLE MEMBER (
mem_id NUMBER NOT NULL,
mem_name VARCHAR2(100) NOT NULL,
gender varchar2(10) NOT NULL,
age NUMBER,
hire_date DATE,
etc varchar2(500),
CONSTRAINT mem_pk PRIMARY KEY(mem_id)
);
-- MEMBER 테이블에 연습 데이터 추가
INSERT INTO MEMBER
(mem_id, mem_name, gender, age, hire_date)
VALUES
(1, '선덕여왕', '여성', 23, to_date('2023-02-01', 'YYYY-MM-DD'));
INSERT INTO MEMBER
(mem_id, mem_name, gender, age, hire_date)
VALUES
(2, '허난허설', '여성', 33, to_date('2023-02-01', 'YYYY-MM-DD'));
INSERT INTO MEMBER
(mem_id, mem_name, gender, age, hire_date)
VALUES
(3, '김만덕', '여성', 43, to_date('2023-02-01', 'YYYY-MM-DD'));
INSERT INTO MEMBER
(mem_id, mem_name, gender, age, hire_date)
VALUES
(4, '장희빈', '여성', 35, to_date('2023-02-01', 'YYYY-MM-DD'));
INSERT INTO MEMBER
(mem_id, mem_name, gender, age, hire_date)
VALUES
(5, '신사임당', '여성', 45, to_date('2023-02-01', 'YYYY-MM-DD'));
-- 추가한 데이터 조회
SELECT * FROM "MEMBER" m ;
① UNION ALL 예제
-- UNION ALL 예제
-- 두번째 테이블은 EMPLOYEE 테이블 사용
SELECT e.EMP_ID , e.EMP_NAME, e.GENDER, e.AGE
FROM EMPLOYEE e
UNION ALL
SELECT m.MEM_ID , m.MEM_NAME, m.GENDER, m.AGE
FROM MEMBER m ;
-- EMPLOYEE 테이블의 신사임당의 정보 수정
UPDATE EMPLOYEE SET EMP_NAME = '신사임당'
WHERE EMP_NAME LIKE '신%';
-- ID값을 기준으로 오름차순 정렬 (첫번째 테이블의 컬럼명 기준)
SELECT e.EMP_ID , e.EMP_NAME, e.GENDER, e.AGE
FROM EMPLOYEE e
UNION ALL
SELECT m.MEM_ID , m.MEM_NAME, m.GENDER, m.AGE
FROM MEMBER m
ORDER BY EMP_ID ;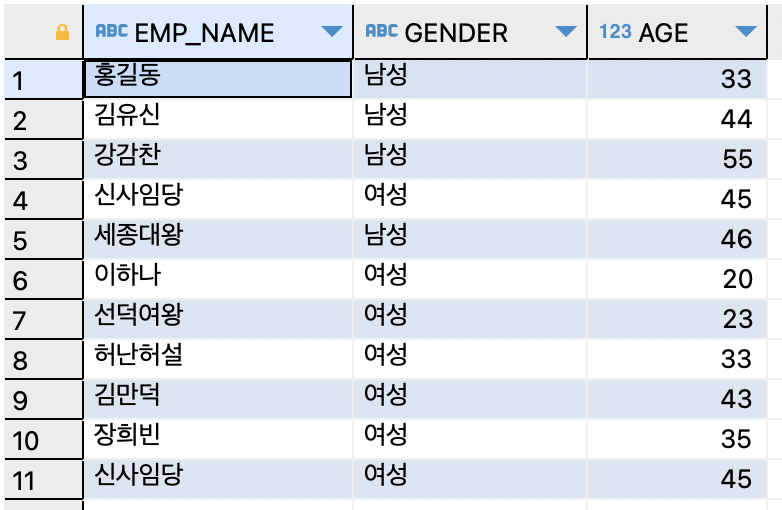
② UNION 예제
-- UNION 예제
-- 신사임당의 정보가 중복되므로, 집합연산자 'UNION' 사용 시 중복된 데이터 출력되지 않음
SELECT e.EMP_NAME, e.GENDER, e.AGE
FROM EMPLOYEE e
UNION
SELECT m.MEM_NAME, m.GENDER, m.AGE
FROM MEMBER m ;
- 데이터 무결성 특성으로 이름은 동일하지만, ID값이 다르므로 서로 다른 데이터로 취급됨
-- 이름은 동일하지만, ID값이 다르므로 중복된 데이터로 여기지 않음
SELECT e.EMP_ID, e.EMP_NAME, e.GENDER, e.AGE
FROM EMPLOYEE e
UNION
SELECT m.MEM_ID, m.MEM_NAME, m.GENDER, m.AGE
FROM MEMBER m ;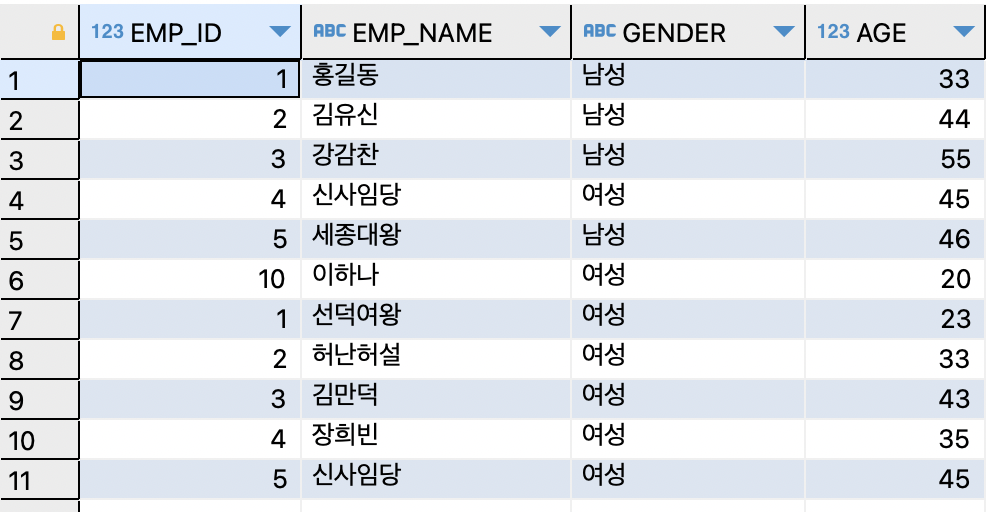
③ INTERSECT 예제
-- INTERSECT 예시
SELECT e.EMP_NAME, e.GENDER, e.AGE
FROM EMPLOYEE e
INTERSECT
SELECT m.MEM_NAME, m.GENDER, m.AGE
FROM MEMBER m ;
④ MINUS 예제
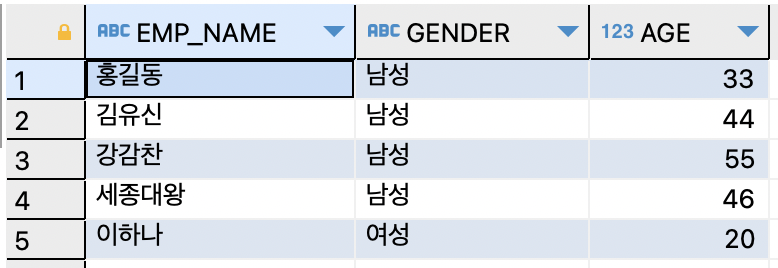
-- EXCEPT 예시
-- EMPLOYEE 테이블에만 속하는 사람 조회
-- 1) 첫번째 테이블 조회
SELECT e.EMP_NAME, e.GENDER, e.AGE FROM EMPLOYEE e ;
-- 2) 집합연산자 (EXCEPT) 이용
-- : 첫번째 SELECT문의 조회 결과에서 두 번째 SELECT문의 조회 결과를 제외한 행을 출력함
-- ∴ 첫번째 테이블에서 '신사임당'의 데이터를 제외한 나머지 데이터 출력
SELECT e.EMP_NAME, e.GENDER, e.AGE
FROM EMPLOYEE e
MINUS
SELECT m.MEM_NAME, m.GENDER, m.AGE
FROM MEMBER m ;
- EMPLOYEE 테이블과 MEMBER 테이블 둘 중 하나에만 속하는 사람 조회
-- 접근 방법 : 합집합에서 교집합 제거
(SELECT e.EMP_NAME, e.GENDER
FROM EMPLOYEE e
UNION
SELECT m.MEM_NAME, m.GENDER
FROM "MEMBER" m )
MINUS
(SELECT e.EMP_NAME, e.GENDER
FROM EMPLOYEE e
INTERSECT
SELECT m.MEM_NAME, m.GENDER
FROM "MEMBER" m );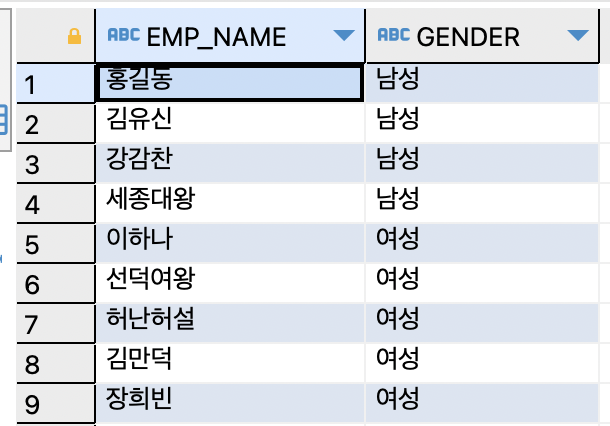
'백엔드 > Oracle' 카테고리의 다른 글
| Oracle : SQL ( INNER JOIN ) (0) | 2023.07.14 |
|---|---|
| Oracle : SQL ( INSERT / DELETE / UPDATE 확장 / COMMENT ) (0) | 2023.07.13 |
| Oracle : SQL ( CASE WHEN THEN / GROUP BY ) (0) | 2023.07.11 |
| Oracle : SQL ( 날짜형 함수 / 형변환 함수 / NULL 처리 함수 / GREATEST, LEAST, DECODE / WITH절 ) (0) | 2023.07.10 |
| Oracle : SQL - 내장 함수 (0) | 2023.07.07 |